Rcan 详解
总体概要
RCAN(Very deep residual channel attention networks)又名非常深的残差通道卷积网络),可以说这一个模型将残差和通道注意力使用得恰当好处。在图像超分领域里面,一张低分辨的图像含有大量的低频信息,而仅仅包含少量的高频信息,而超分任务的难点就是从低频的信息推断出丢失的高频信息。所以如何地让网络更加地注意高频的信息就是一个突破点。作者在此篇文章中介绍了:
-
使用残差跳线连接使得低频信息更快地通过网络
-
使用残差的残差来构建更深的网络使得网络能够有足够的深度去恢复高频信息
-
使用通道注意力使得网络能够优化通道之间的关系,使得重要通道拥有更高的优先度(假设指偏向于含有高频信息的通道)
网络构成
数学表达
首先输入$I_{LR}$,使用一个一层的卷积Conv提取出浅层特征$F_0$
\[F_0 = H_{SF}(I_{LR}),\]而后使用一个嵌套很深的RIR模块$H_{RIR}$提取深层特征$F_{DF}$,这个提出来的RIR块达到了所见的模型中的最深的深度,提供了非常大的视野域。
\[F_{DF} = H_{RIR}(F_0),\]然后对提取出来的深层特征使用一个上采样的操作,将图像长宽变大,这儿使用的上采样方法是Sub-Pixel上采样(将$r^2$个通道的像素值排列到rw$\times$rH的图像中)
\[F_{UP} = H_{UP}(F_{DF}),\]上采样得到的上采样特征再通过一个一层的卷积层得到最后的输出,称之为重建过程
\[I_{SR} = H_{REC}(F_{UP}) = H_{RCAN}(I_{LR}),\]损失函数
RCAN使用了$L_1$的损失函数,给定一个训练集$\lbrace{I_{LR}^i,I_{HR}^i}\rbrace_{i=1}^N$,其中含有N张LR输入和它们对应的HR输出。整个训练RCAN的过程就是减少下面的$L_1$损失函数
\[L(\theta) = \frac{1}{N}\sum_{i=1}^N \Vert H_{RCAN}(I_{LR}^i) - I_{HR}^i \Vert_1,\]图文描述
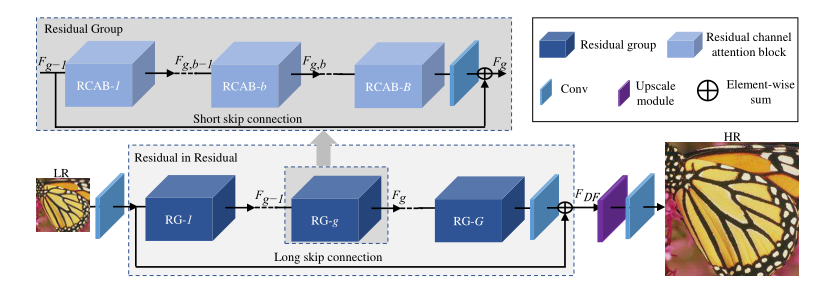
如上面的公式中提到,整个RCAN由四个大的部分构成,分布是提取浅层特征的单层卷积、提取深层特征的RIR模块、上采样模块和重建模块。其中RIR模块最复杂,其它的层都是一层的卷积或者像素排列层构成。
RIR模块
RIR模块意为残差中残差,首先是一个RIR模块有G个RG模块,然后每个RG模块有B个RCAB模块。RG模块外部有一个长残差连接LSC,RCAB模块外部也有一个较短的长残差连接SSC,与此同时在RCAB里面存在着更小的残差连接,以此来构成残差中的残差。
残差的好处是LSC和SSC能够将低清图片中非常多的低频信息更加容易地通过恒等映射连接到输出。同时恒等映射也使得构建更深的网络变得可能,使得网络在非常深的情况下依然可以学习。在这里RIR达到了超过400层的深度。
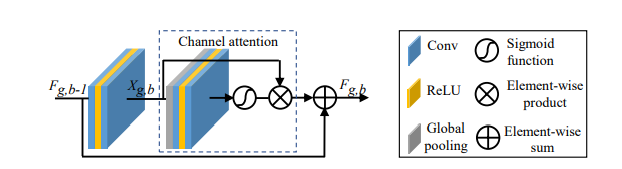
RCAB模块
在RCAB模块里面,作者使用了残差的通道注意力。如下图,特征输出进来过后存在两个跳线连接,第一是特征直接跳线输出到后面层进行相加,第二是经过了卷积过后在跳线中进行通道注意力的操作,将前面的特征经过学习出来的通道注意子rescale。
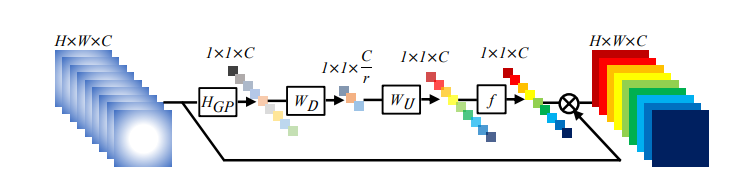
其中通道注意子的学习过程如下,将通道特征$x_c$通过全局池化变成c个通道的通道描述子$z_c$,然后通过一个通道下放缩$W_D$和上放缩$W_U$,在这个过程中学习到通道的互关系,在放缩之间使用Sigmoid和ReLu激活函数增加其非线性(注意不要使用softmax,softmax不具有非线性,而是一种one-hot激活),最后得到的通道统计子$s$,将输入的原始通道数据乘以通道统计子得到放缩后的通道信息$\hat{x}_c$,即为通道注意力。
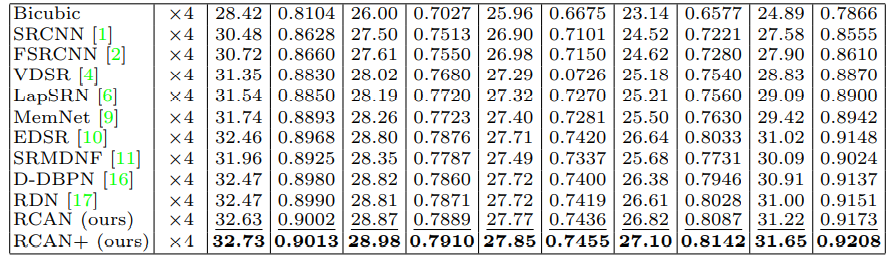
RCAN效果