图像超分技术路线
图像超分技术路线
卷积理解
卷积可认定为一种矩阵线性变换,连续并排的卷积可以认为是一种推理过程。另外卷积存在着不同的种类,如:
-
卷积核大小不同
-
卷积步长
-
卷积稀疏
可以理解的是,不同的卷积种类只是为了提高解决方法命中度,而增多的通道数也仅仅是提升了解空间大小。
问题定义
设\(ConvX\) 为一个卷积核,它代表着一种特定的信息映射关系,一个复杂的深度学习任务就是要找到大量的有逻辑关系的卷积核 \(ConvX_{0,1,2,...}\) ,这里的卷积核存在着一种关系\(R\) ,代表着卷积核的一种排列顺序。那么总体的深度学习任务可以用以下公式代表:
\[I_x \cdot \mathcal{R}(ConvX) = I_{y^{'}}\]\(I_x\)代表神经网络的输入,\(I_{y^{'}}\)代表神经网络的输出,\(I_x\)经过了关系\(\mathcal{R}(ConvX)\)卷积网络运算过后输出\(I_{y^{'}}\)。
深度学习的学习过程——反向传播方法,更像是一种数学上的反推法,将标准答案\(I_y\)以反向传播的梯度的形式传播回去,使得上述关系\(\mathcal{R}\)得到展开并更新。为了学习到关系\(\mathcal{R}\),其关键在于如何去判定某个卷积为有效卷积,或者去判断某个卷积关系为有效关系。
反向传播方法可以是解决上述问题的一种方案,但是它仍然有它的不足的地方,与此同时我们的一大批研究是在反向传播方法的这么一个大前提下,来针对网络针对问题地提升深度学习的效率。
反向传播方法的缺点
使用反向传播方法来学习参数容易使得靠近输出的层学习很快,靠近输入的层学习很慢。同时在层数增大的情况下,容易在训练开始出现梯度爆炸在训练结束的时候出现梯度消失,使得神经网络的训练变得非常困难。
另外反向传播的方法使得网络只能是前馈网络,决定了网络的流向方向是一个方向,网络的结构限制在了一种单向扩展的复杂度之中,使得每一层网络只能被利用一次,信息只能向前流动,而不能构成更加复杂的任意流向的网络。
问题解决
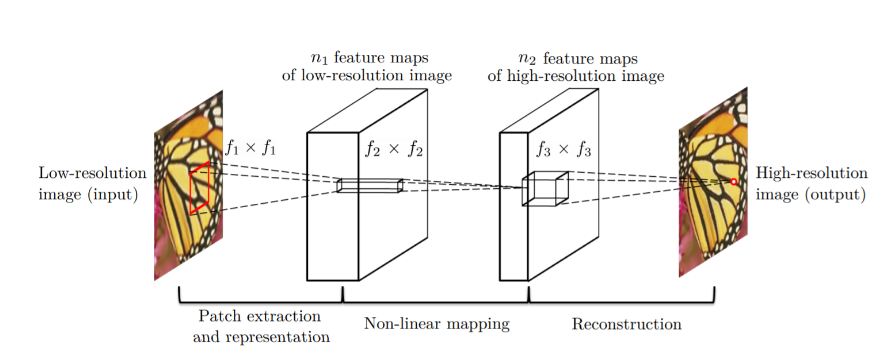
采用CNN卷积神经网络的方法相较于传统的机器学习方法能够带来更大的学习效果,SRCNN是一个简单的CNN架构,它仅仅由三层网络构成,分别是特征提取层、非线性映射层和重建层。输入一个低分辨图像过后,特征提取层从输入提取出一系列的特征图,然后通过非线性映射层即为1x1的卷积核将多个通道变小并增加非线性,最后通过重建层即反卷积把图像放大得到高分辨图像。
增加网络深度
在一定程度下对网络增加深度,可以使得网络中的卷积核顺次推理变得更具有鲁棒性,在纵向上的各种卷积核组合下,其网络产生的非线性非常高,能够完成一些非常复杂的问题的输入输出映射,所以,对于一个复杂问题,其纵向深度一定要符合其输入输出非线性度要求。
不过,无畏的增加网络深度会导致梯度消失或者梯度爆炸,网络难以训练等问题。一个网络的纵向深度应该符合输入输出非线性程度。
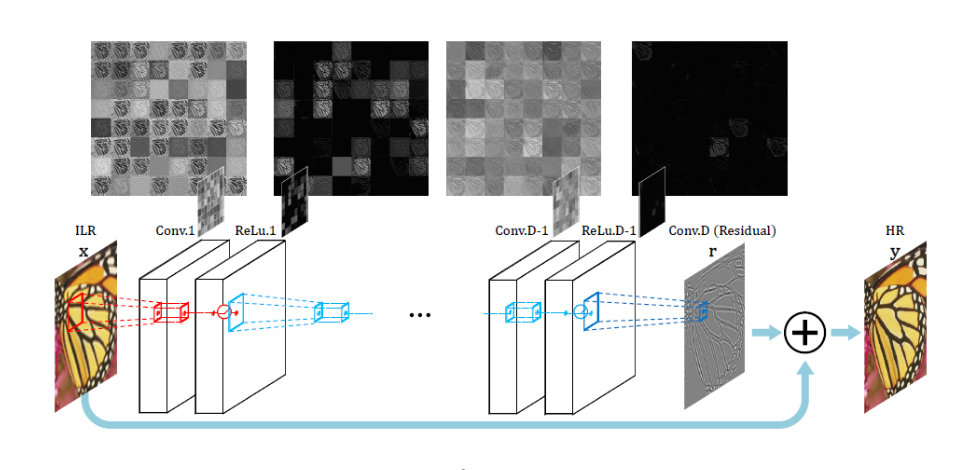
VDSR使用了更加深的网络并且基于VGG使用了更加小的3x3的卷积核,整个网络显得更加深且使用更加小的卷积核,同时在网络的末尾尝试去学习输入图像和插值图像的残差关系,而不是一种直接的从头到尾的映射。
增加网络的宽度
增加网络的宽度就是增加网络中的通道数,增宽的通道代表着增加的卷积核个数,在相同深度下更多的卷积核个数能够提升网络对问题的解空间。设\(\mathcal{L}\)层网络每层网络分别具有\(X_i\)个通道,那么其问题的解空间便是:
\[\mathcal{S} = X_1 \cdot X_2 \cdot X_3 \cdot ...X_\mathcal{L}\]可以看出,在确定了合适的网络深度过后,加宽的网络能够容纳更多的问题解,使得网络能够更加具有拟合数据集的能力。
卷积核大小
大的卷积核能够拥有更大的感知野,但是同时也拥有更高的计算复杂度,事实上,在长宽减小的卷积过程中,加深的小卷积核网络一样能够获得大卷积核的感知野,所以目前来说3x3的卷积核是最优的选择,或者使用谷歌的Inception网络的深度可分离卷积,将3x3可拆分为1x3卷积和3x1卷积,将会更加减小计算量。
另外类似于多通道不同卷积核的网络,其目的是在下一层能够同时感知到不同视野的信息,但是就前面提到的,这样的设计可以等同于多层网络的残差。 设特征图\(\mathcal{F}_{3x3}\) 、\(\mathcal{F}_{5x5}\)、\(\mathcal{F}_{7x7}\) 为\(\mathcal{F}_{in}\)在不同卷积核卷积得到的特征图,而在3x3的卷积下,如果步长设置为2,padding设置为1,那么其特征图\(\mathcal{F}_{out}=\mathcal{F}_{in}/2\),那么其在下一层的感知野实则为上一层的2倍,即6x6,再下一层的感知野为9x9,如果再通过残差连接,第三层的特征图为
\[\mathcal{F}_{L3}=\mathcal{F}_{3x3} + \mathcal{F}_{6x6} + \mathcal{F}_{9x9}\]即通过小的卷积核加上残差网络同样能够实现对特征图拥有不同的感知野。
残差连接
网络的残差使得网络能够在学习过程中形成一个等映射函数,当前面的任何通路学习到了有用的信息过后,都能够通过跳线连接迅速地前馈到输出层,在此可以防止网络过深的时候的梯度爆炸或者梯度消失。另外残差连接也是一种多通路的设计,在已有通道不变的情况下,通过残差连接,我们能够拥有更多组合的通路连接,提升了通道的利用率。
递归网络
递归学习是使用共享的网络权重,在网络中重复地进行相同的卷积,这里的假定的是某些问题的复杂度是来自于一个基础的映射的堆叠,所以我们可以去寻找这样的一个嵌套结构。递归网络的另外一个好处就是节省内存空间,在运行的时候能够拥有更快的推理速度。在小型网络上可以尝试使用此机制。
通道注意力
通道注意力是一种获取通道相互关系并扩大相关通道信息的一种方法,通过一个最大池化和平均池化得到的通道描述子,将通道描述子经过全连接和sigmod激活便得到了通道激活矩阵,使用这个矩阵乘上原来的通道来达到对相关通道的扩大和抑制。这种方法同样是一种改善通道利用率的方法,利用反向传播的梯度来改变注意到更加重要的通道。
对抗网络
对抗网络由一个生成器和一个判别器构成,生成网络的输入可以是一种噪音分布也可以是其它任何的条件输入,经过生成器采样生成一种约束条件下的输出,生成器的输出又会和groundtruth组成二分类问题,输入到判别器网络中,将生成器的输出判别为假就是判别器的任务,通过最小化生成损失和最大化判别损失来使得对抗网络按照目标要求生成特定的图像或者做图像翻译工作。
相关工作
EDSR

EDSR(Enhanced Deep Residual Networks)是一种借鉴了ResNet的残差机制在图像超分上面的一次尝试,其网络将之前的网络足够深,同时拥有比较多的残差模块,所以其在图像超分上面的表现超出了当时的所有模型。EDSR还有两个比较显著的改进就是在残差跳线上移除了BN层,减少了BN层的网络能够节省更多的计算开支并且对于图像超分这种low-level的应用,Batch正则化很有可能会移除掉网络中学习到的高频信息。为了使得更大的残差模型训练变得更加稳定,在残差处做了残差放缩,设置了0.1的放缩比,即只允许0.1的残差信息通过跳线流到下一层。
RCAN
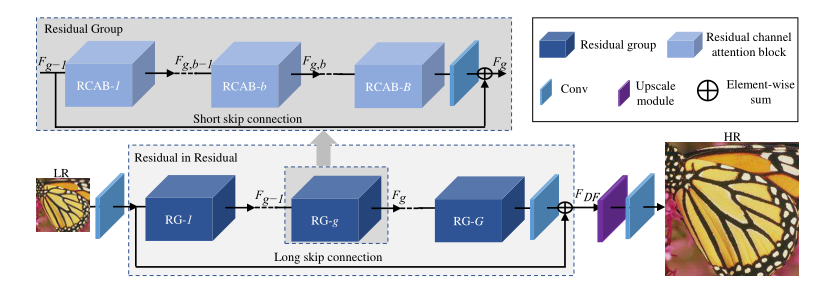
RCAN——深度残差通道注意网络,是通过一种residual in residual(RIR)的结构来形成非常深的网络,网络在大的方面由几个残差群和残差构成,而每个残差群又是由更小的卷积、通道注意力和残差构成。通过这样的一种嵌套的结构,可以将更加复杂的网络建立起来,同时拥有残差以及通道注意力机制,能够使得每一个通道都尽可能地参与到网络的训练之中来。虽然RCAN是更深的网络,但它的参数比EDSR和RDN的参数少,并且其性能效果也更加好。
SRGAN
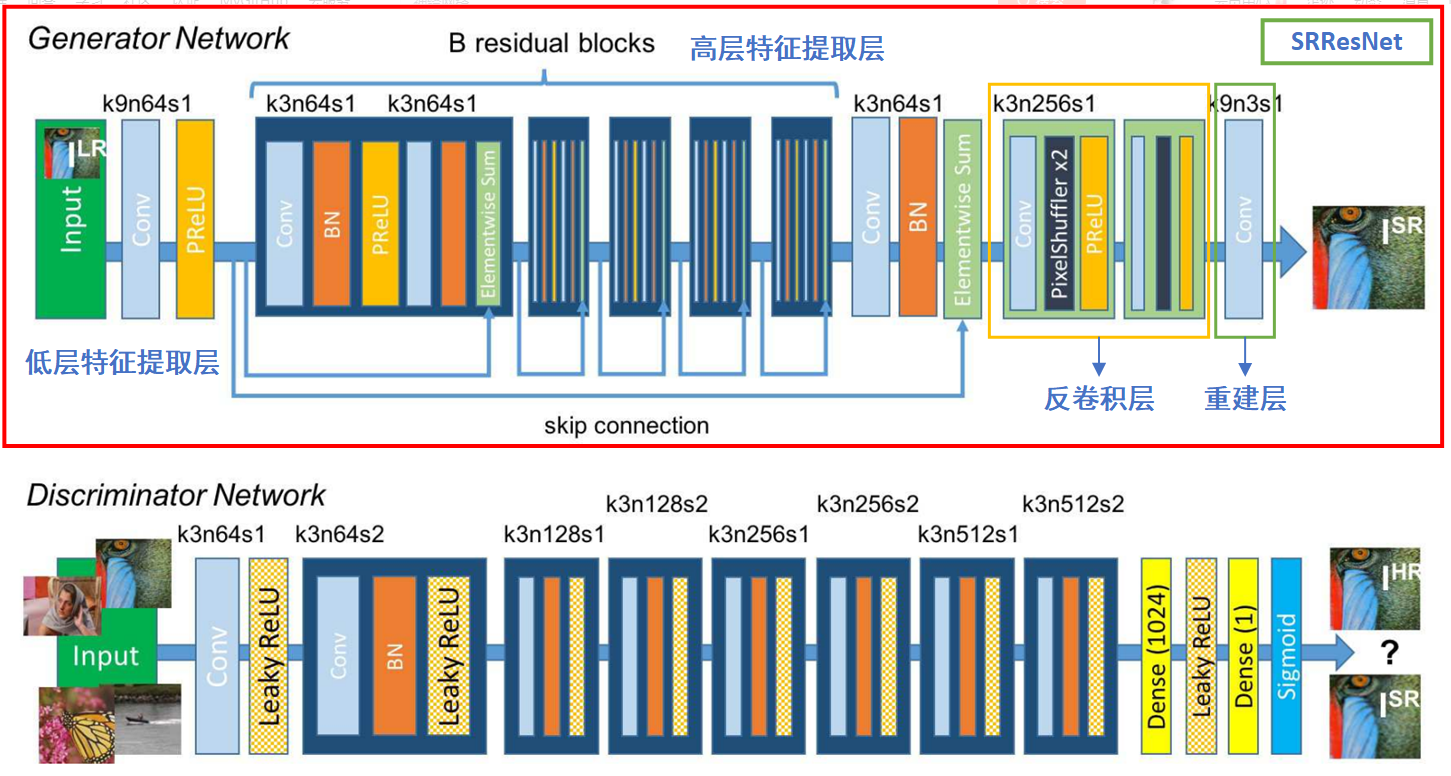
SRGAN是一种采用生成对抗网络来实现图像超分的网络结构,其主体由SRResNet构成的生成网络以及一个简单分类网络构成的判别网络,SRGAN网络其重要贡献在于其对训练网络的损失函数的改进,就以往的经验来看,psnr值得增高不一定能够相比其它psnr值小的图像拥有更好的感知,所以SRGAN提出一种感知损失,感知损失一般由三部分构成:内容损失和对抗损失。内容损失主要有两种,一种是像素级别的MSE损失,另外一种是特征图级别的VGG损失,这儿的VGG损失是指将生成网络产生出来的输出输入到预训练了的VGG-19网络得到feature map和高清标签输入到VGG网络产生的feature map做loss,这种loss更能反应图片之间的感知相似度。另外的对抗损失便是判别器分类损失的负log值。
虽然SRGAN的psnr值并不是很高,但是其MOS(平均主观评分)非常高,这说明SRGAN方式的损失函数可以值得借鉴,而我们评价SISR网络的指标也不能够太单一。
EDRN
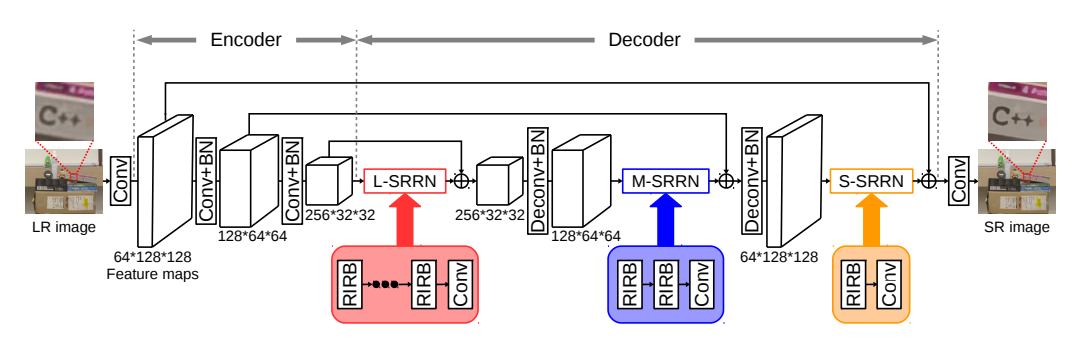
EDRN(Encoder-Decoder Residual Network)采用了编码解码的结构减小中间运算量,同时使用RIR(Residual in Residual)结构构建更深的残差网络,在内部残差中加入通道注意力机制,提升通道信息交互度。采用这种方法的结构其网络在超分过程中对高频信息的恢复表现得更加良好,其编码解码结构能够将更多得高频信息得到保留,虽然总体来说psnr值并不是特别理想。